

当你在初次观察一副完全陌生的图片时,会将有限的注意力资源聚焦于哪一区域呢?比如,你在欣赏下面这副风景照片时,会将注意力聚集在岸上的房屋而不是远方的风景之上。看似简单的瞬间判断是由人体复杂的视觉注意力机制所控制。

(来源:Pixabay)
视觉注意力机 ********* 为人类视觉神经传递过程中处理大脑信号的独特机制,用视觉迅速扫描出全景图像,捕获需要重点关注的目的区域,并将更多的注意力投入到注意力焦点区域,捕获更多目标的细节信息以及忽略掉相比之下不重要的信息。
上述的人类注意力相关机制在计算机中已被普遍采用。核心目标也是通过算法从庞杂的信息库中筛选出对当下正在进行的目标任务最重要的信息群。
但是,将目前普遍应用的注意力机制应用于处理大型图像仍困难重重。
这是因为,计算机在处理像素过高的图像(例如,1080p)时,60% 的计算时间都用在注意力矩阵的创建和应用过程中,效率普遍较低。
近日,Meta AI 团队提出了多头注意力机制,可作为视觉转换器(ViT,Vision Transformers)应用过程中的高效注意力机制,助力了上述问题的解决。

(来源:Computer Science)
近期,相关论文以《多头高效注意力机制》(Hydra Attention:Efficient Attention with Many Heads)为题发表在 Computer Science 上。

将多头注意力发挥到极致
据悉,研究者将模型中的特征(Feature)个数与注意力头(Head)个数设置成相同值,创建出线性多头注意力模块。
由于多头注意力模块中没有隐藏的常数,在视觉转换器中明显比标准注意力模块的速度快了一个标记计数因子。
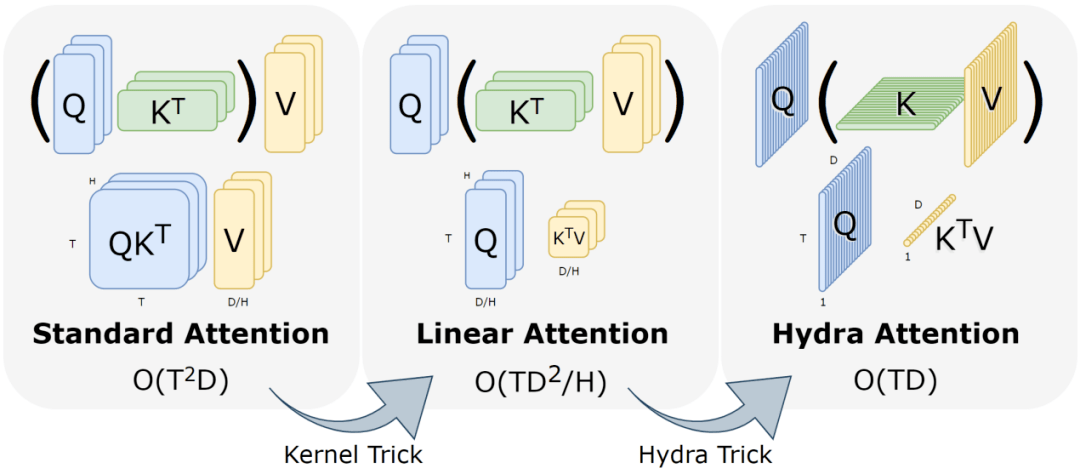
(来源:Computer Science)
如上图所示,在标准注意力模块中,当注意力头(Head)数等于标记数的平方(O(T2d))时,用可分解核(decomposable kernel)可以重新安排顺序,使 Head 数转变成特征数 D 的平方。
在多头注意力运算过程中,通过上文提到的特殊设置,能够使注意力头数量更大化,即 H=D,可将运算转变成空间和时间上产生 O(TD)的简单化操作。

多头注意力提升运算速度与准确性
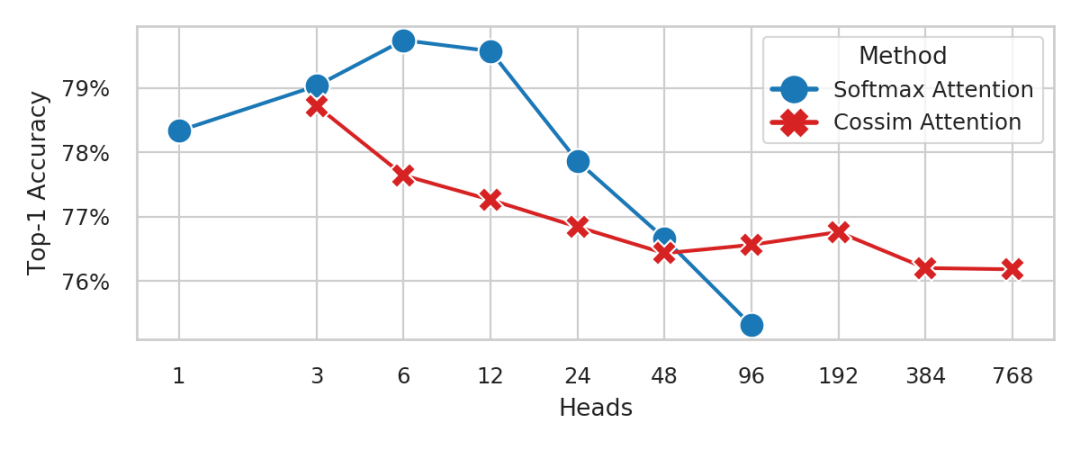
(来源:Computer Science)
研究者还通过数据直观展示出多头注意力之中的应用模型,相较于普通注意力模型具有更优化的性能。
他们分别使用了标准注意力和多头线性注意模型,分别用蓝线和红线表示,在图像数据集上运行出具有不同 Head 头数的演示模块。
根据统计数据显示,标准注意力在 Head 数大于 96、多头注意力在 Head 数小于 3 时出现内存不足的状况。
数据的不同意味着,当向模块中加入 Head 头数量变多时,标准注意力模型具有较差的准确度,而多头线性注意力模型仍可以保持准确度不变。
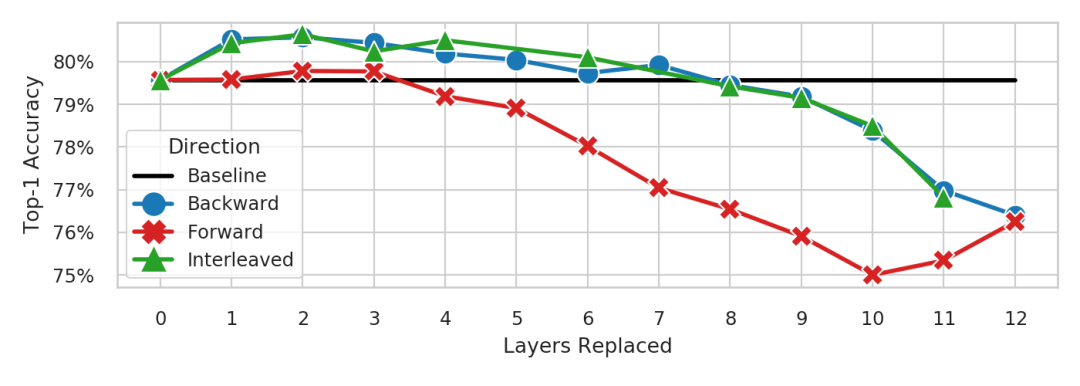
(来源:Computer Science)
或者在模块的运行过程中替换成不同的层,多头注意力也可以将模型精确性提升约 1% 或维持稳定(与基准线相比)。
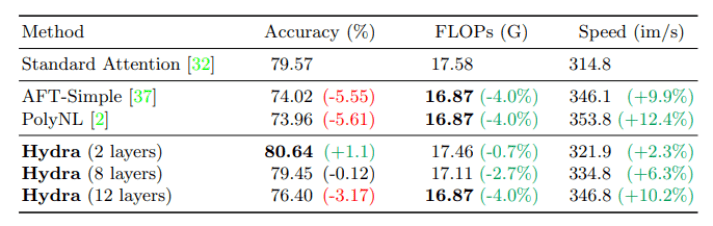
(来源:Computer Science)
在 ImageNet 图像数据库上对 224px 像素的图像进行处理时,运用不同的内核(AFT-Simple 或 PolyNL),多头注意力精度下降更小。
此外,如果不替换 ********* 中的每一个注意层,多头注意力也能够在提高准确性的同时,减少每秒浮点运算数 (Flop )或增加吞吐量、提升运算速度。
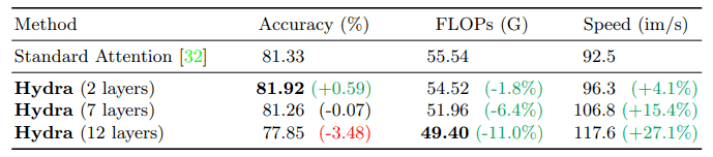
(来源:Computer Science)
在另一组对比实验中,研究者在 ImageNet 图像数据库上用 384px 像素的图像对 30 个训练过程进行微调操作。多头注意力仍然可以在只有 2 个图层的情况下提升 0.59% 准确率(与基线相比)。
而与基线准确率相匹配的情况下,在图层数为 7 层的时候,多头注意力能够提升 15.4% 的吞吐量。
(来源:Computer Science)
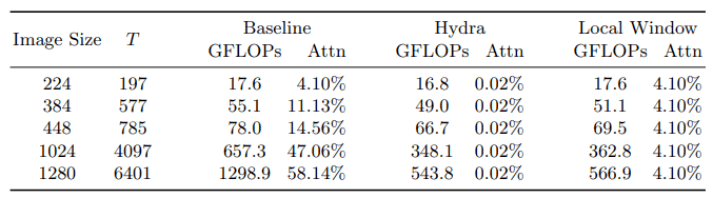
在每秒浮点运算数量与图像大小的对比实验中,研究者记录了随着图像像素大小的增加,以及不同注意力模式下每秒浮点运算数、创建和应用注意力矩阵数量所占总量的百分比。
数据表明,多头注意力与局部窗口注意力机制在处理大图像过程中显著提升了模型的每秒浮点运算数量。在此过程中,多头注意力的限制是它只比局部窗口注意力速度快 4%,但却能产生更高的吞吐量。
未来,研究者将会探索多头注意力在标记更密集领域内的应用,如检测或分割视频。此外,它是一种通用技术,可以进一步提升应用程序的速度,在掩码预训练或标记修剪过程中发挥出相应的作用。
